AI翻唱教學丨AI歌手/合成歌曲教學懶人包!AI孫燕姿一鍵練成
AI翻唱教學
AI歌手教學丨原理
AI歌手教學丨前期準備:AI歌手訓練
AI歌手教學丨中期準備:製作目標歌曲
AI歌手教學丨正式製作:AI翻唱歌曲
AI翻唱歌手原理
AI翻唱歌手是通過深度學習等人工智能技術實現的。具體來說,首先需要將原始歌曲作為訓練數據,並使用神經網絡對其進行訓練。訓練完成後,AI翻唱歌手可以模擬原始歌曲中的聲音、語調和情感,並在其基礎上進行歌曲的重新演繹。
AI翻唱技術雖然能夠實現音色模仿,但是演唱技巧的訓練仍然很困難。例如,AI尹光在翻唱林家謙的《一人之境》中的Hey,是通過使用Sovits替換人聲進行生成的。生成的音軌只包含人聲,並不包含伴奏。因此,需要再將人聲和伴奏放進混音軟體中進行融合,同時在後期處理的過程中,還可以加入一些元素,如AI尹光的Hey、呀等字。
前期準備:AI歌手訓練
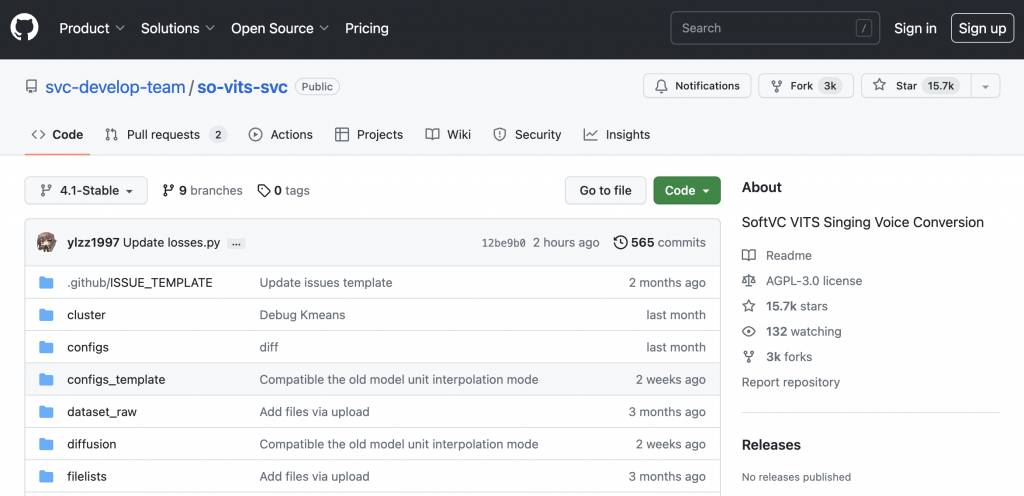
步驟一、So-vits-svc
So-vits-svc (又稱 Sovits) 是基於 VITS、soft-vc、VISinger2 等開發的開源免費 AI 語音轉換模型。
使用者只要輸入人聲樣本,So-vits-svc 模型就會學習及掌握所輸入的人聲的音色和發音特點等,訓練出使用者想要的語音模型。最近不少 AI 翻唱作品就是建基於這個 so-vits-svc 開源項目,目前可使用Github或Google Colab最的So-vits-svc為方便。
步驟二、下載歌手音源
應使用無損音檔作為AI歌手模型訓練素材,如ALAC、WAC等格式檔案,或直接下載FLAC,MP3檔則不能。
步驟三、Vocal 人聲/Music 背景音 分離
將歌曲的背景音樂與人聲分離,因為AI歌手模型訓練只需要人聲,背景音樂會影響模型的推理效果,分離後將可減少雜音。要將歌曲中的人聲與音樂分離,簡單方法可以使用線上工具去除人聲和背景音樂:
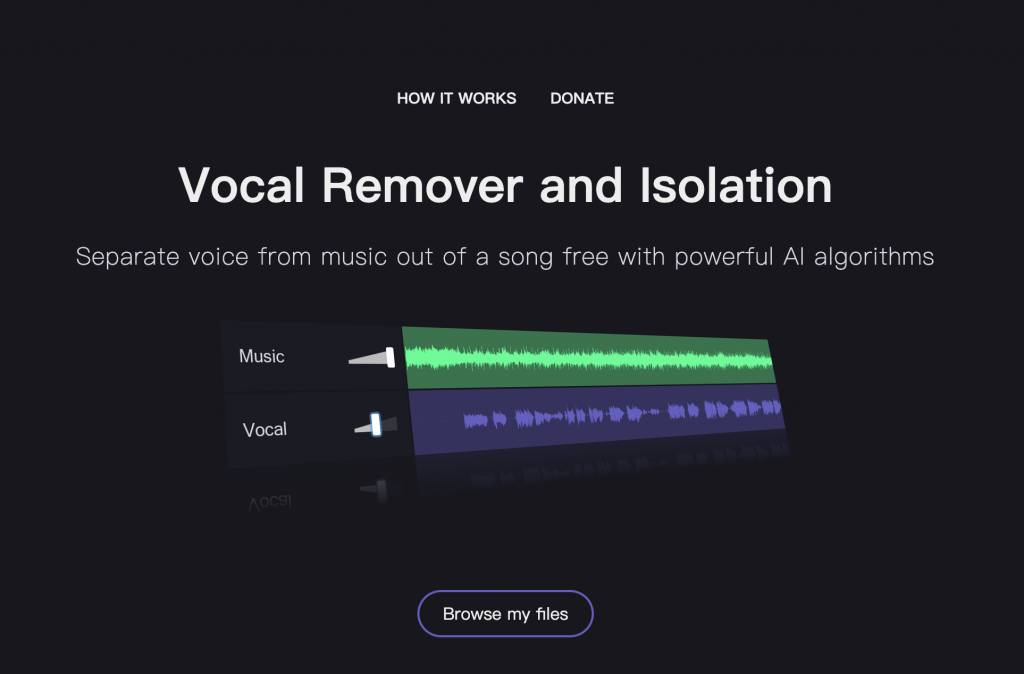
AI伴奏分離工具:Vocal Remover and Isolation
- 進入網站後,點撃 Browse my files上傳歌曲。
- 上傳需時 1-2 分鐘,完成後,會見到兩條音軌,上方綠色音軌是音樂,下方紫色音軌是人聲。
- 選擇下載 MP3 或 WAV 格式。
- 分別選擇人聲及背景音樂,點撃 Save 完成下載 。
步驟四、將已分離 Vocal 人聲分割
高品質音頻檔案大小比較大,為了讓AI順利學習,需要把歌曲切割成十多個10秒左右的音檔,否則運算過程有機會會暫停。要留意可先把把一首歌分為 3-4段,因為一首歌等前奏 Intro、間奏 Inter、結尾 Outro都沒有人聲,如直接切割有機會會影響AI歌手模型訓練成果質素,同樣可使用AI工具一鍵協助分割音源檔案:
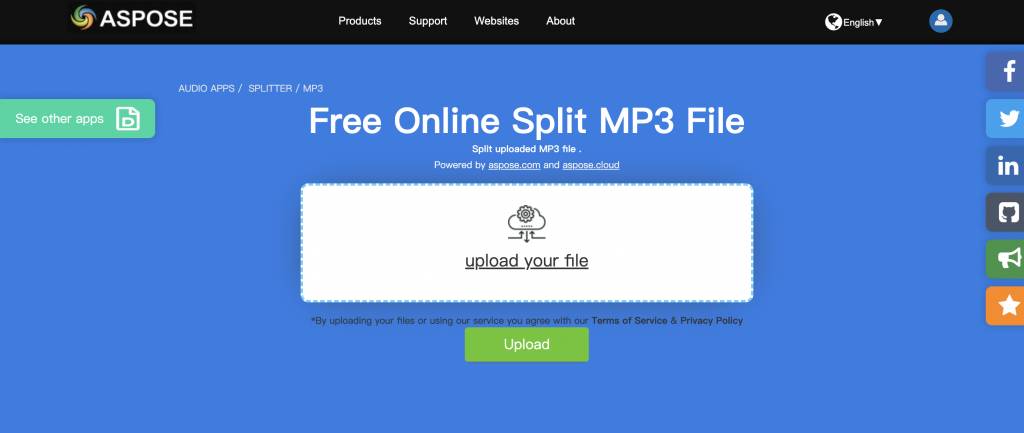
- 進入ASPOSE網站上傳人聲,然後點撃 Upload。
- 把下方的紅線拉到 1 分鐘位置,然後點撃右側的 “Add Splitter Point” 。
- 點撃 “Add Splitter Point” 後,會見到下方出現另一條紅線,將紅線拉到 2 分鐘位置,點撃右側的 “Add Splitter Point” 。
- 選擇下載格式,然後點撃 Export 完成下載 。
步驟五、訓練AI歌手模型
- 把切割好的音源檔放進一個文件夾裡
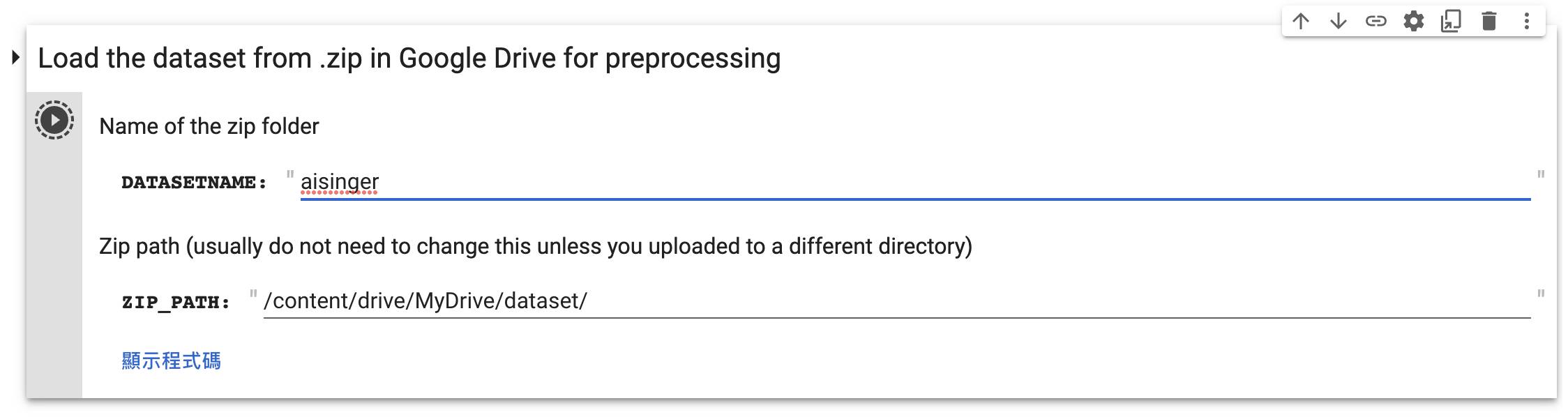
- 再把文件夾壓縮,然後任意命名,如「aisinger」
- 到自己google帳戶drive中開啟一個文件夾命名為「dataset」
- 把已壓縮的文件檔放進去
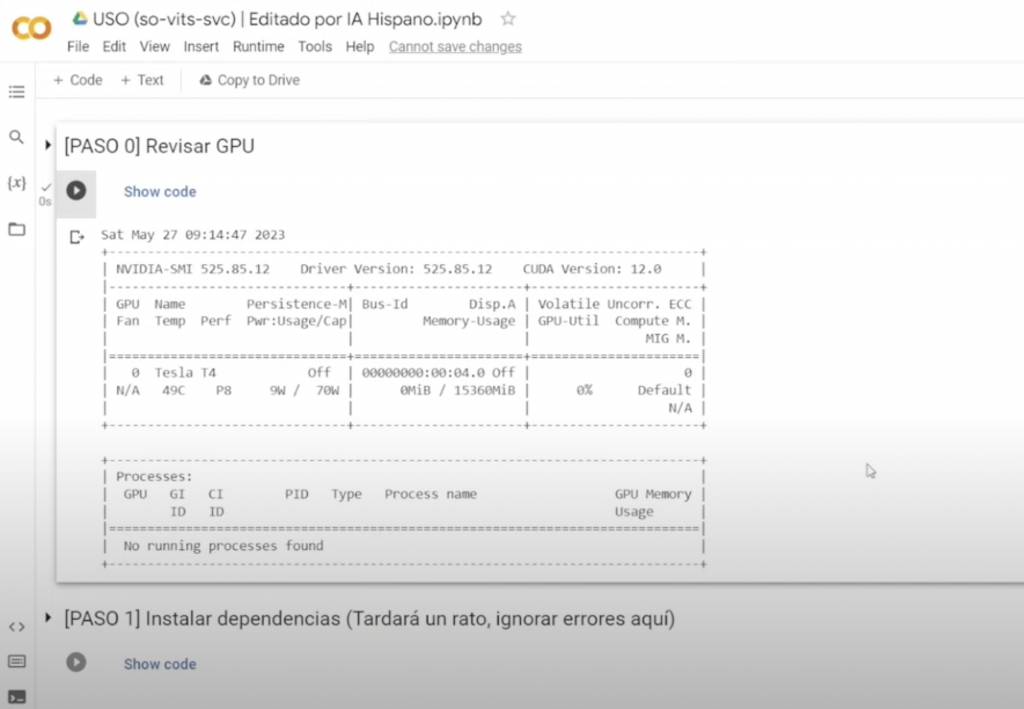
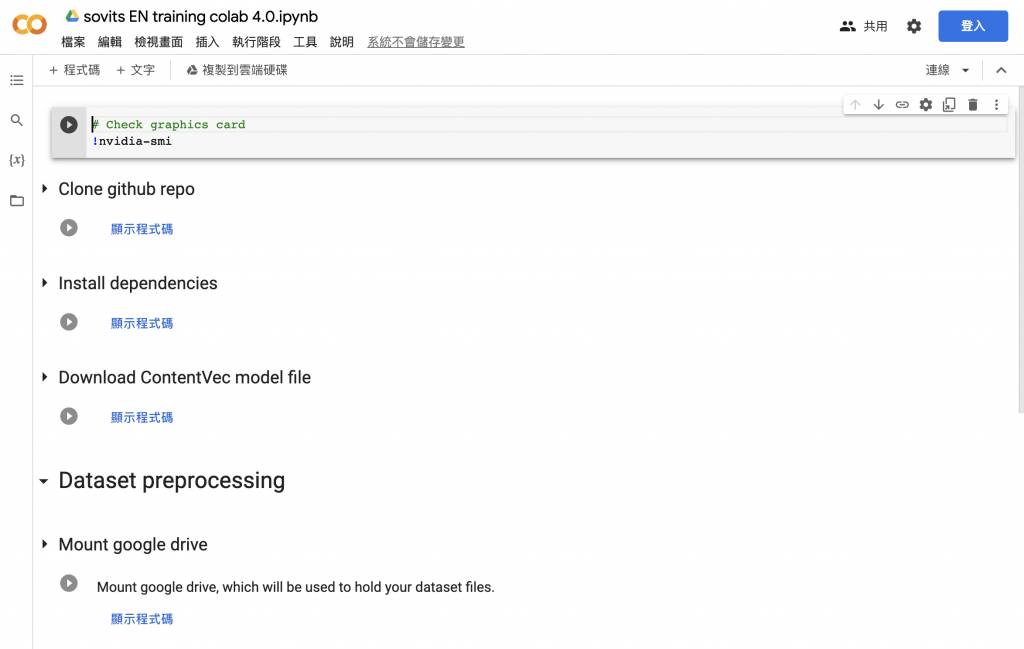
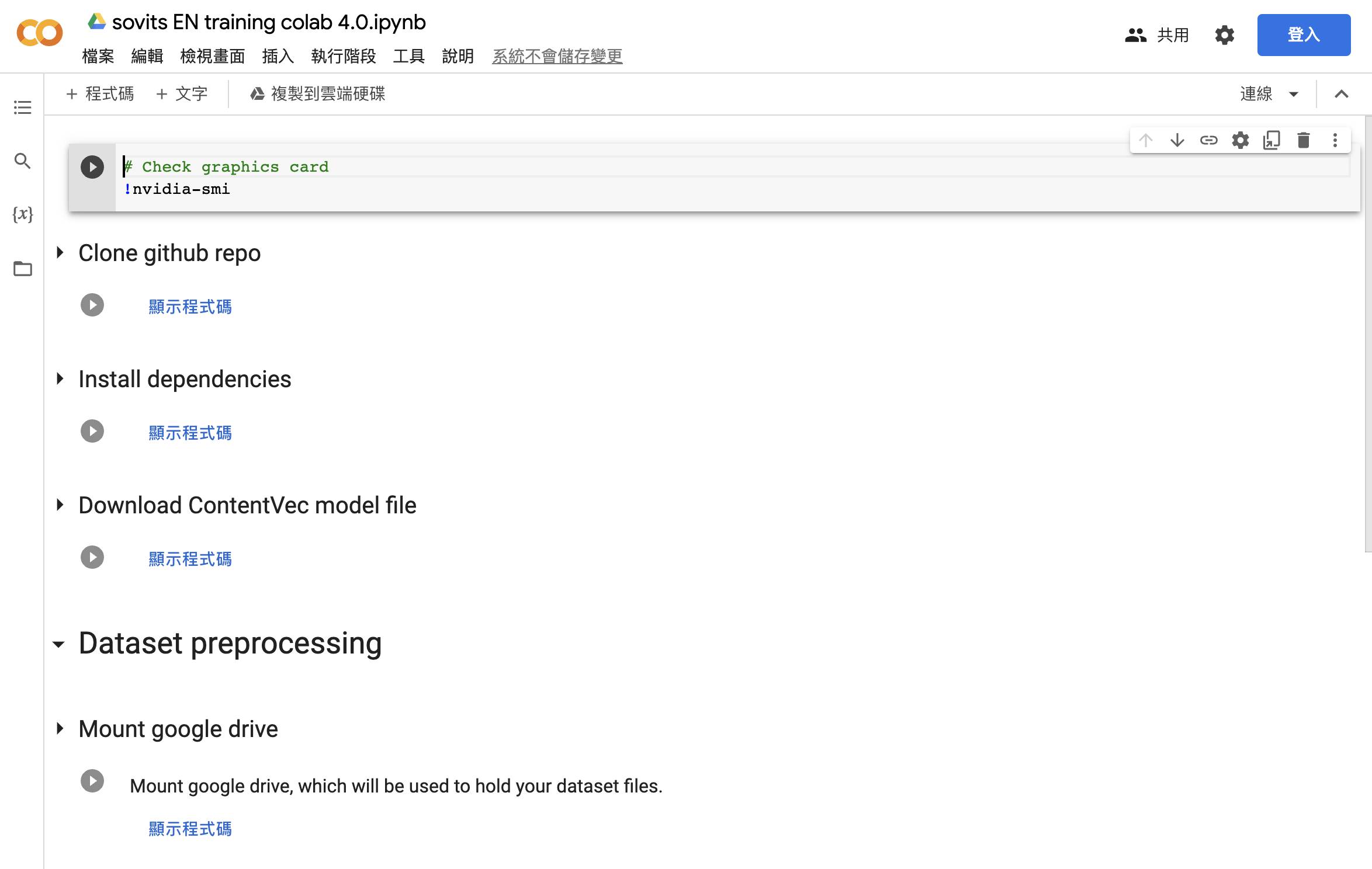
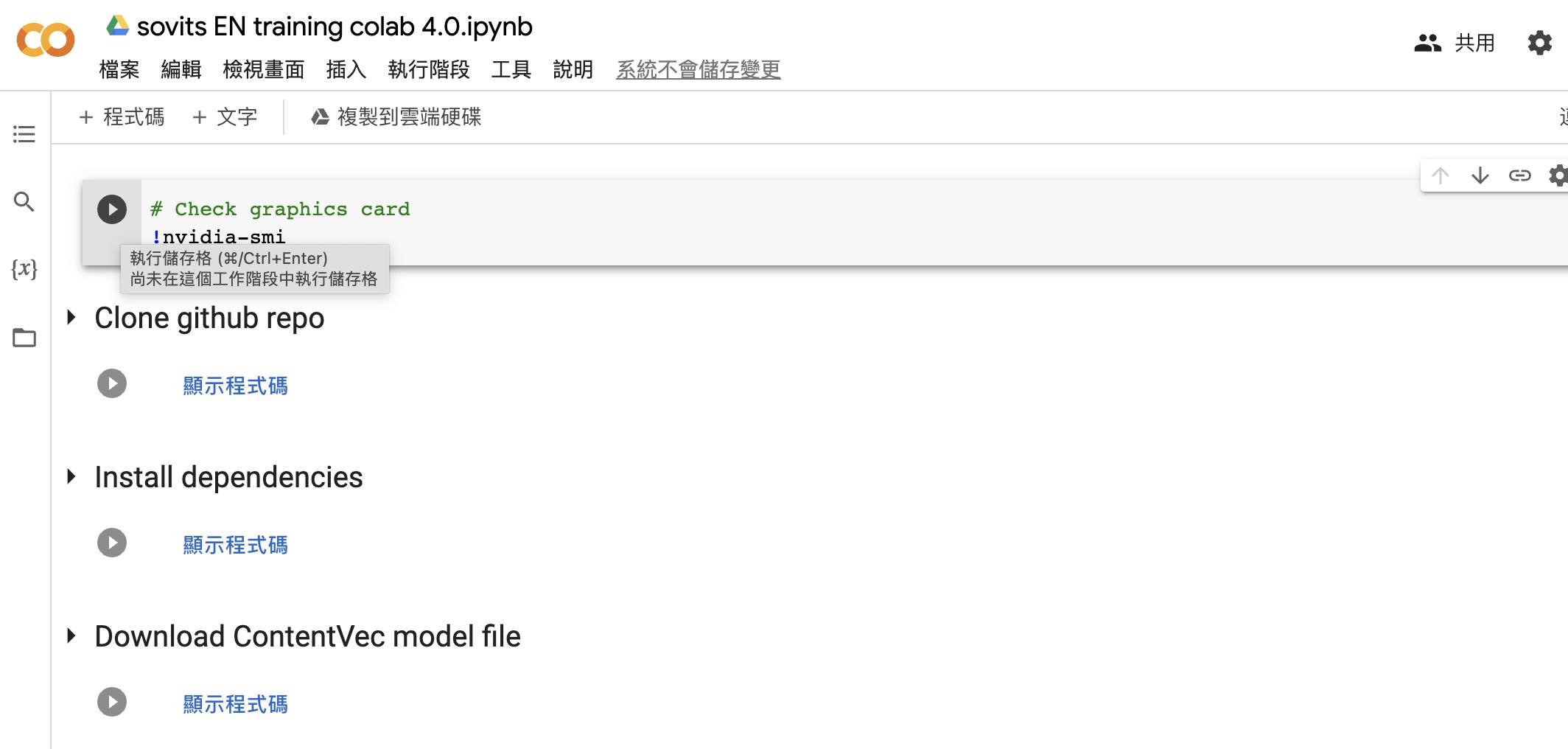
- 接著到Google Colab So-vits-svc中點擊頁頭「Check graphics card」中的Play圖像
- 按「仍要執行」
- 依序把頁面上的「Clone github repo」、「Install dependencies」、「Download ContentVec model file」的Play圖像都點一下
- 在「Datasetname」中輸入文件夾名稱(aisinger)再按Play圖像
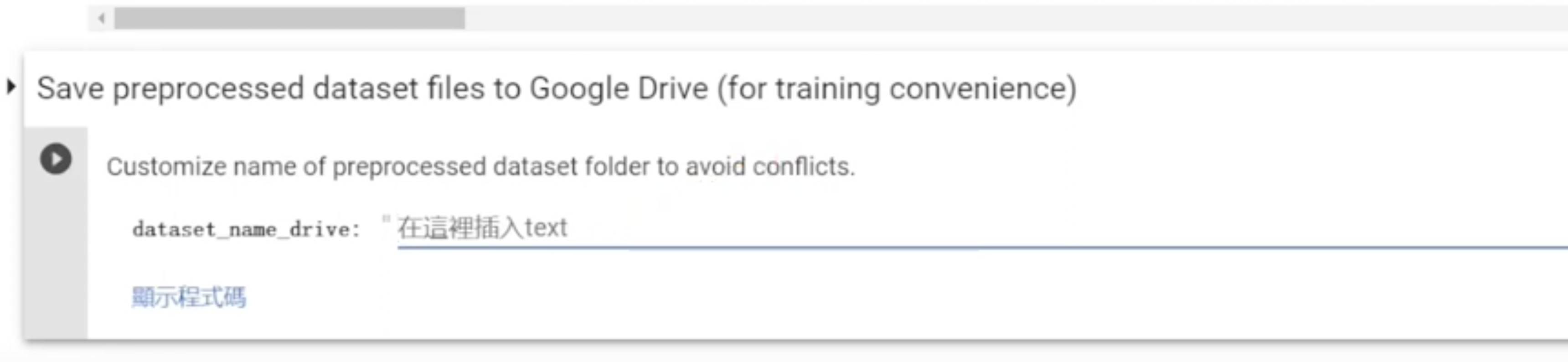
- 在「Dataset_name_drive」中任意輸入另一個檔案名稱,如「aisinger_final」
- 點擊下方「Training」中的「Save to drive」再按Play圖像
- 最後在「Start training」中再按Play圖像即可
中期準備:製作目標歌曲
步驟一、下載音源
同樣下載相關音源,例如想把已製作的AI歌手演唱《一人之境》,則下載一段完整的音源檔案
步驟二、Vocal 人聲/Music 背景音 分離
同樣再把 Vocal 人聲及 Music 背景音分離,用作AI翻唱歌曲
正式製作:AI翻唱歌曲
步驟一、把已替換 Vocal 人聲音軌放入軟件中